
Context Is More Than A Length-Measuring Contest
It's not about the size of the context, it's about how well your model can use it.

OpenAI’s initial release of ChatGPT had a maximum context length of 4096 tokens, soon upgraded to 32,768 tokens with the release of GPT-4. ChatGPT shocked the rest of the players into action, and a few months later Anthropic released Claude, a model with a context window of 100,000 tokens. Not to be outdone, OpenAI pushed to 128,000 tokens with the release of GPT-4 Turbo; alas, their time on top was short-lived, as just a few weeks later the 200,000-token-context Claude 2.1 arrived. And a new challenger was right around the corner: Deepmind’s Gemini 1.5 came out swinging with a 1,000,000-token context announcement, and when it was released to the public a few months later, it supported 2,000,000 tokens. For over a year, this record held. But Meta’s recently-announced Llama 4 Scout model usurped the throne once more, boasting a context window that can support 10,000,000 tokens.
A clash of giants, a storm of engineering, a whirlwind of progress. Healthy competition that drives the field forward, allowing contexts to surge from 4,000 to 10,000,000 in just two and a half years. This is a powerful narrative that underscores our rapid advance towards an AGI-powered future.
At least, it seems that way. But do those context numbers mean anything?
Car manufacturers report the miles-per-gallon of their vehicles. When a new car is released, the MPG number will be highlighted in articles about the vehicle, because this information is helpful for fuel-conscious consumers. This is a great state of affairs all around, and so when an AI company reports the context length of a new LLM, it’s not unreasonable to treat that number in the same way as one would treat a car manufacturer’s MPG report.
Miles-per-gallon has some crucial attributes: a concrete physical definition, universally-standardized measurements, and externally-verified assessments. As we will see, none of these are true of context lengths. The context length is selected at the full discretion of the model provider, and does not directly translate into any specific property of the LLM. A claim like “our new LLM has a context length of 1M” is much more akin to Automotive Weekly giving the new Toyota an 8.5, than it is to Toyota reporting that their new sedan gets 30 MPG. We let Toyota tell us the MPG, but we don’t let Toyota give their own car an 8.5 — for obvious reasons. That would merely incentivize companies to rate their own cars as high as they thought they could get away with, leading to massive inflation on reported scores regardless of underlying improvement.
Well, whenever a model with a state-of-the-art context length is announced, the entire tech-media ecosystem uncritically reports that this number implies new capabilities, while everyone reports LLMs falling short at long contexts. In practice, people building tools around LLMs typically stop putting tokens into the context well before the stated limits.1 Perhaps we should stop trusting model providers to report their own context lengths.
Let’s take a closer look and understand what’s really going on.
A good place to start is to ask where the reported context lengths come from. When a new model is released, and its creator claims that the maximum context length is X, how is X determined?
A common misconception is that X is in some sense a “hard limit” to what the model can predict. In fact, no such bound exists. Every sequence model — from the mightiest transformer to the humblest RNN — represents a distribution over all sequences, with no upper bound on the length. You can give any model a context of any length, and ask it to predict the next token, and it always will give you an answer.
So why does the idea of a maximum context length come up at all? There are two straightforward reasons: cost and quality.
Inference for transformer-based models grows more expensive as more context is ingested, and eventually this cost becomes prohibitive: many GPUs are required, and many engineer-hours are needed to properly coordinate the GPUs. So for purely practical reasons, it is to the benefit of any given inference provider to cut off users at some context length.
But quality is the more fundamental reason. A moment ago, I mentioned that any model can turn a context of any length into a prediction. But it’s important to realize: they won’t all be good predictions. Predictions are good only for contexts that are sufficiently similar to contexts seen during training, allowing generalization to kick in. If we try to do inference using contexts much longer than any seen during training, generalization breaks down, and the predictions become horrible. But this is a gradual process. Along the way, we simply see the model getting worse and worse at utilizing the extra tokens of context it was given.
For these two reasons, model providers are forced to choose a maximum context length. This an ad-hoc choice, carried out by each model provider individually.2 There is no standardization across model providers (or even across multiple models from the same provider) as to how a stated maximum context length translates into concrete capabilities.3 The actual chosen number is based not just on cost and quality, but other concerns including, of course, PR and marketing. And when announcing that your model has long context gives it a free huge marketing boost, it is not so surprising that all the big players are doing so.
So we can’t trust the reported context-length numbers as being inherently meaningful. But that does not mean that no progress has been made! It just means we will need to be more careful in our assessment.
The central value of a long-context LLM is that adding information to the context can improve the quality of the response. A few familiar examples: prompting with more details about your expectations makes it more likely that you will get the expected output; demonstrate a task a few times, and the model gains the ability to complete that task as desired; giving samples of your writing enables new writing to be generated in your style; putting an entire book into the context improves the model’s ability to summarize that book.
A natural way to define for the context length of a LLM is as the maximum number of tokens that can be used to increase its performance in this way. But unfortunately, this definition is inadequate. First of all, there is no particular maximum token-count number after which performance stops improving — typically, what we observe as we add more tokens of context is a gradual decrease in marginal improvement.4 Secondly, and even more fundamentally, it is impossible to measure performance in a task-neutral way.
A model that gets big benefits all the way up to 10k context when asked to summarize a book, might nonetheless fail to get meaningful benefits from more than 1k context when asked to generate writing in a particular style. Is the context length of that model 10k or 1k? There’s no meaningful answer.
To develop a real understanding the capabilities and limitations of a long-context model, we must evaluate it holistically. There is no shortcut, no “one true test” that will produce a perfect scalar metric of context length. All we can do is measure its performance on a variety of useful tasks.
One valuable tool for doing so is an in-context learning (ICL) curve. Here is an example:

This is a fairly typical ICL curve. In this figure, you can see how adding examples to the context translates into improved performance on the task. Improvement is fastest at the beginning, but persists across the tested range.
By constructing ICL curves for a variety of different metrics, we can start to build a picture of how well a model can leverage additional context. Let’s take a look at a few popular choices.
The most fundamental metric for any LLM is its training loss, which is typically the negative log-likelihood of data scraped from the Internet. Minimizing this metric is the focus of the pretraining phase, which is when almost all of the LLM’s knowledge is acquired, so strong ICL on the training loss correlates well with strong ICL on many other tasks.
Below is an example of a train-loss ICL curve for the Gemini model (lower is better), which is stated to have a 1M-token context window. We see in-context learning on training loss up to 32k tokens, but a gradual flattening out. (The curve extending to 1M tokens was not published.)

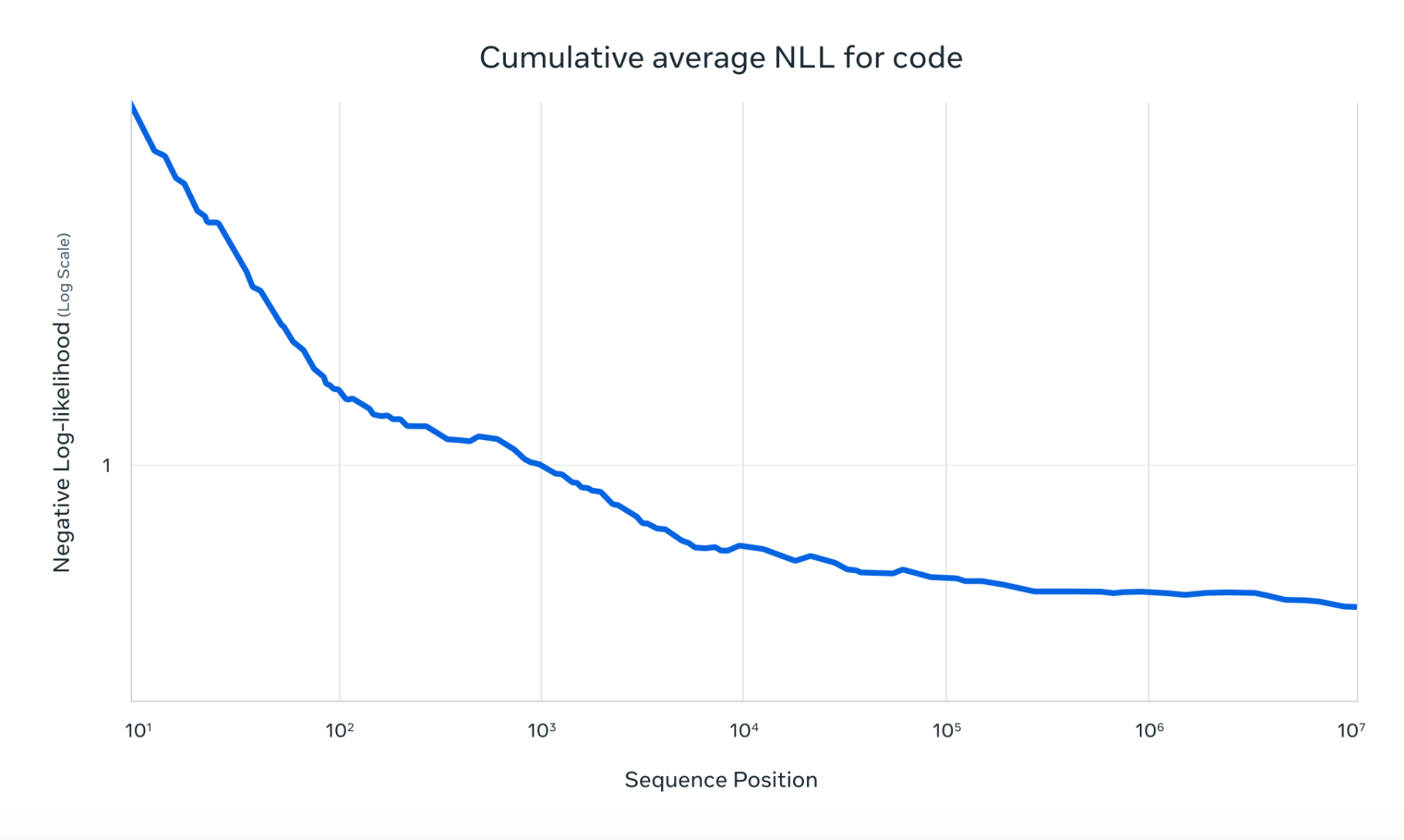
Below is a second example: the train-loss ICL for Llama 4, whose context length is reportedly 10M. We see solid ICL up to 300k, and a small amount further ICL up to 10M. This reflects the improvement in code quality one can expect between showing Llama 4 a 10k-token context (e.g. the current file), a 300k-token context (e.g. the history of recently-viewed files), or a 10M-token context (e.g. the entire codebase).
A second task commonly used to evaluate is needle-in-a-haystack. In this task, a special password (the needle) appears at a random point in the middle of a long context (the haystack), and the goal is to simply recall the needle. To visualize the results, rather than using a 1-d ICL curve, it is common to also convey information about where the model makes mistakes via a 2-d grid. The x-axis indicates the total context length, while the y-axis indicates whether the needle appeared at the start or end of the context.
Below are examples for Gemini and Llama, where in both cases we see near-perfect performance. This is an example of a task where these models excel, reaching their stated context lengths with little issue.


One reason why the performance on this task is so consistent is that the model providers know that users of their models often have needle-in-a-haystack-like tasks, and so typically some training is devoted specifically to mastering this ability. But several interesting evaluation benchmarks have been proposed, such as Nvidias’ RULER and Adobe’s NoLiMa, which extend the idea of needle-in-a-haystack in various ways. On these task variants, which are less likely to have been directly targeted during training, LLMs seem to be less capable. Below are examples of performance curves on multi-hop variable tracking, using the Yi-34B model (higher is better).

We see a steep decrease in performance as the task is attempted over longer contexts. In general, LLMs on these tasks tend to see severe performance degradation between 25%-50% of their reported context lengths.
One of the most powerful attributes of LLMs is their ability to turn extra tokens of context into improved performance. But this ability isn’t something that can be objectively quantified by a single number, and letting model providers choose a number for themselves has turned it into something of a vanity metric. The current state of LLM evaluation is somewhat chaotic — there are projects like Chatbot Arena and Open LLM Leaderboard, but no clear way to understand what the best model is for any given task. The field could really use a Wirecutter-style publication for LLM reviews, evaluating each new model in a standardized way on tastefully-selected tasks, and summarizing the ability with a consistent (but ultimately subjective) numerical score.
Our research at Manifest AI focuses on a family of architectures that replaces transformers’ attention layer with a linear-cost alternative called power attention, making it possible to train long-context models much more cost-efficiently. Unlike the other linear-cost attention variants, power attention models show in-context learning across the entire context. This opens the door to a new generation of models that are trained end-to-end on extremely long contexts and show great in-context learning ability as a result.
Standard practice is to use retrieval techniques (RAG) to place a relevant subset into a small context, or to break up the desired context into chunks to be processed independently and recombined.
My understanding is that typically, they go with the longest context seen by the model during training. But this can be misleading; for example, Llama 3 was described as having a context length of 128k despite >95% of training data using context 8k, just because a little bit of longer-context training happened at the end.
The most you could say is that, for a model claimed to have a maximum context length of X, the inference-time infrastructure of that model’s provider allows you to submit documents of up to X tokens before cutting you off. But this is a very weak criteria, and says more about the inference provider than the model itself. For example, if we evaluated by this criteria, every open-source model (such as the Llama family) would have infinite context because you can set up your own inference for those models, and process as many tokens as you want.
After enough tokens, performance will sometimes start to degrade. But even when this degradation occurs, it does not really make sense to consider this inflection point the “maximum context”, as the model stops getting value from additional tokens well before this point.